Every quality engineer trusts their SPC software. But non-normal data breaks that trust — and your software won't tell you.
Run a dataset through any major SPC package — Minitab, JMP, InfinityQS, even Excel with an add-in — and it computes Cpk instantly. Clean number. Two decimal places. Looks authoritative. But behind that number is an assumption the software never asked you about: that your data follows a .
Minitab offers non-normal options. EntropyStat is distribution-free. Those aren’t the same thing. Offering a menu of distributions to choose from is distribution-flexible — not distribution-free. Here’s why that distinction determines whether your Cpk is correct.
For 60–80% of industrial datasets, it doesn't. And the software knows this. It just doesn't care.
The Default Nobody Questions
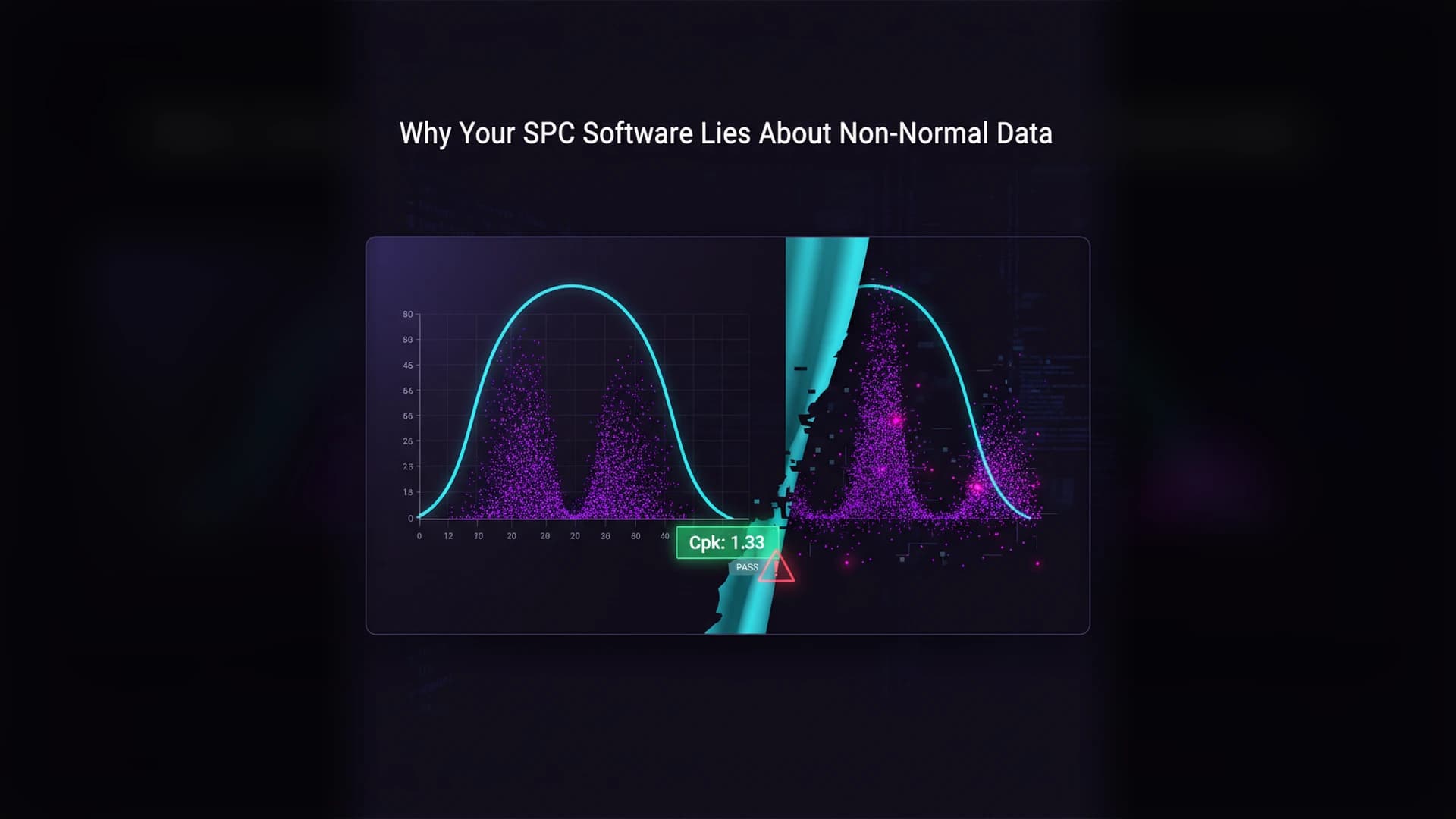
Open any SPC tool. Load your measurements. Click "Capability Analysis." What happens?
The software estimates a mean (μ) and standard deviation (σ) from your data, assumes those parameters describe a Gaussian bell curve, and computes Cpk = (USL - μ) / 3σ. That formula is correct — if the data is normal. If the data is skewed, bounded, heavy-tailed, bimodal, or any of the other shapes that real manufacturing processes produce, the formula gives you a number that has no statistical meaning.
Not "slightly off." Meaningless. The Cpk formula doesn't degrade gracefully with non-normal data. It produces a confident-looking number that can be catastrophically wrong in either direction. And non-normal data is the majority of what manufacturing produces.
Your software doesn't flag this. It doesn't warn you. It doesn't even run a normality test by default. It prints the number and moves on.
What Non-Normal Data Actually Looks Like
If you've worked on a shop floor, you've seen these shapes — you just might not have connected them to the normality problem.
Right-skewed dimensions. Machining near a physical stop produces measurements that bunch up against a boundary and trail off in one direction. Hole diameters, surface roughness, coating thickness — all naturally skewed. Force a bell curve onto this and you overestimate the probability in one tail while underestimating the other.
Bimodal distributions. Multi-cavity molds where each cavity runs at a slightly different mean. Day shift vs. night shift with different setups. Material lots with different properties. Pool the data and you get two peaks — but your software sees one wide bell curve.
Bounded data. Concentrations can't go below zero. Roundness can't go below perfect. When your process runs near a physical limit, the data piles up against the bound and the tail is chopped off. A Gaussian fit extends past the bound into impossible territory, distorting tail probability calculations.
Heavy tails. Intermittent disturbances — tool chatter, fixture slippage, measurement artifacts — add occasional outliers that inflate σ and widen the apparent distribution. Traditional Cpk absorbs these into the bell curve instead of treating them as distinct events.
These aren't edge cases. They're the majority of industrial datasets. Distribution fitting studies across automotive, aerospace, and pharmaceutical manufacturing consistently find that more datasets fail normality tests than pass them.
The Lie Has Two Faces
When your software forces a normal model onto non-normal data, the error goes one of two directions. Both cost money.
False confidence. Your skewed machining data produces traditional Cpk = 1.45. Above 1.33. Capable. Ship it. But the true defect rate in the long tail is three times what the normal model predicts. Those defects show up as scrap, rework, and warranty claims months later. The process capability number was wrong from the start — it just took time for reality to catch up.
False alarm. Your bounded chemical concentration data produces traditional Cpk = 0.92. Below 1.0. Incapable. Management approves $150K in process improvements. But an analysis that accounts for the actual distribution shape shows Cpk = 1.48. The process was fine. The "incapability" was a modeling artifact.
Both scenarios happen. Regularly. And most organizations never discover the error because the wrong Cpk number looks exactly like a right one.
Why the Software Vendors Don't Fix This
They have. Sort of. Every major SPC package offers non-normal capability analysis somewhere in its menus. The problem is the workflow.
Weibull distributions, Johnson transformations, Box-Cox transforms, Clements' method — they all exist as options. But they require the user to:
Suspect non-normality
Run a goodness-of-fit test
Select an alternative distribution from a list
Re-estimate parameters under the new model
Compute capability using the alternative formula
Most quality engineers don't do steps 1 through 5. Not because they're careless — because the software defaults to normal and nobody trained them to question it. The IATF auditor accepted the Cpk number. The customer accepted the PPAP. The process kept running. Why investigate?
The default is doing the damage. And the default is normal.
What Distribution-Free Analysis Changes
The fundamental problem isn't that normal-based Cpk exists. It's that you have to guess your distribution before you can compute capability. Guess wrong and the number is wrong. Even the "advanced" alternatives — Weibull, lognormal, gamma — are still guesses. They're better guesses, but with small samples, you often can't distinguish between them statistically.
Assumption-free statistics eliminates the guessing step entirely. The Entropic Global Distribution Function (EGDF) builds a distribution directly from your measurements — whatever shape they have. No parametric assumption. No distribution selection menu. No wrong-model risk.
If your data is normal, EGDF produces the same result as traditional Cpk. If your data is skewed, EGDF produces the correct result for that skew. If your data is bimodal, EGDF captures both modes. The method adapts to the data instead of forcing the data to adapt to the method.
That's not a feature. That's what "appropriate statistical methods" means — the phrase every quality standard uses but no SPC default implements.
The Number You Report Should Be the Number That's True
Your Cpk goes into PPAP packages. Customer scorecards. Management dashboards. Process improvement decisions. Capital expenditure justifications. Every one of those decisions is only as good as the number behind it.
If that number assumes normality and your data isn't normal, every downstream decision inherits the error. Not "might inherit." Does inherit.
The fix isn't more training on non-normal distributions. It's removing the assumption from the computation entirely.
Upload your process data and see what your Cpk looks like without the normality assumption — actual distribution shape, actual capability, actual risk. Try EntropyStat free →
Distribution fitting replaces the normality assumption with a different guess. With typical sample sizes, Weibull, lognormal, and gamma all pass goodness-of-fit tests — giving different Cpk values. The distribution fitting step that should fix your analysis becomes its own error source.
First pass yield says 98.2%. Cpk says 0.94. One measures what happened. The other predicts what will happen next. When they disagree, something important is hiding — and knowing which to trust prevents costly mistakes.