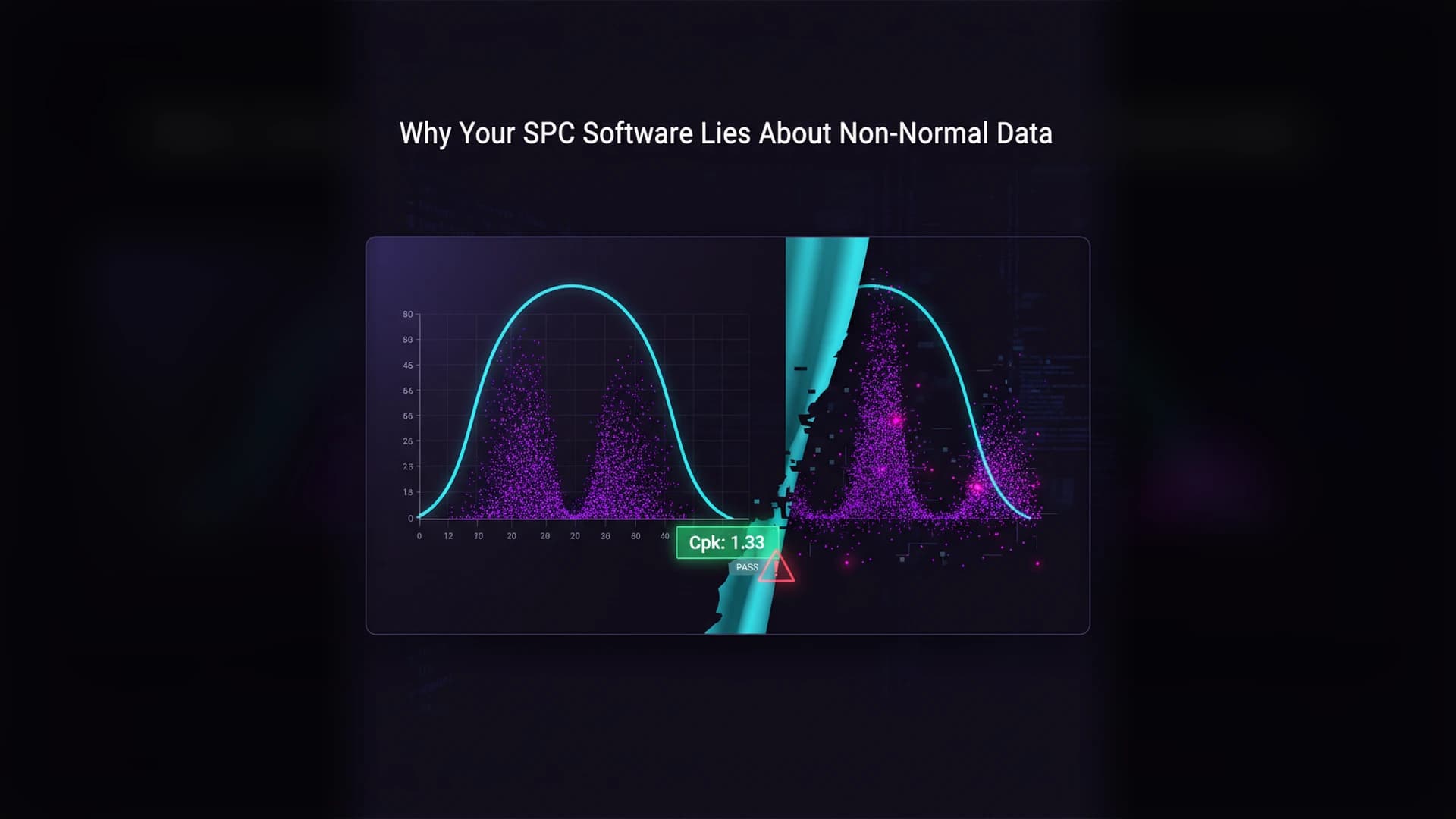
You tested for normality. It failed. Now what — fit a Weibull? A lognormal? A gamma? Welcome to the distribution fitting trap, where the answer depends on which distribution you guess and the stakes are your Cpk number.
Here's the workflow every SPC textbook teaches: collect data, test for normality, and if it fails, select an alternative distribution from a menu. Fit parameters. Run a goodness-of-fit test. Report capability under the new model. Clean, systematic, defensible.
Minitab offers non-normal options. EntropyStat is distribution-free. Those aren’t the same thing. Offering a menu of distributions to choose from is distribution-flexible — not distribution-free. Here’s why that distinction determines whether your Cpk is correct.
Except for one problem. With typical manufacturing sample sizes, multiple distributions pass the goodness-of-fit test — and they give different Cpk values. The distribution fitting step that was supposed to fix your analysis becomes its own source of error.
The Distribution Zoo
Manufacturing processes produce a small number of shapes repeatedly. Knowing which distributions appear where helps — but doesn't solve the selection problem.
Weibull distribution. The workhorse of reliability and wear-out modeling. Tool wear, fatigue life, coating degradation — processes where failure rates change over time. Weibull is flexible (two parameters control shape and scale) but that flexibility means it can look like it fits data that isn't actually Weibull.
Lognormal distribution. Common in particle sizes, chemical concentrations, surface roughness — processes bounded at zero where values spread multiplicatively. Right-skewed by nature. If you take the log of lognormal data, it becomes normal. That mathematical elegance makes it attractive to analysts and dangerous when misapplied.
Exponential distribution. Time-between-events data: time to failure, time between defects, cycle times. Memoryless property — the probability of failure in the next hour doesn't depend on how long the process has been running. Rare in dimensional data but common in process monitoring.
Gamma distribution. Waiting times, queuing processes, accumulated variation. More flexible than exponential (adds a shape parameter) but harder to interpret physically. Often chosen as a "catch-all" for right-skewed data that isn't obviously lognormal.
The problem isn't that these distributions exist. The problem is choosing between them when the data doesn't clearly favor one.
When Goodness-of-Fit Tests Disagree
The Anderson-Darling test is the standard for distribution fitting in SPC software. The Kolmogorov-Smirnov test is the alternative. Both compare your data to a theoretical distribution and produce a p-value.
Run 15 measurements from a machining process through both tests against five candidate distributions. Typical result:
Distribution
AD p-value
KS p-value
Normal
0.02
0.04
Weibull
0.31
0.28
Lognormal
0.44
0.52
Gamma
0.38
0.41
Logistic
0.12
0.09
Normal is rejected (good — it should be). But Weibull, lognormal, and gamma all pass comfortably. Which one do you pick?
The "best fit" approach says lognormal (highest p-value). But p-values from goodness-of-fit tests weren't designed for model selection — they test whether you can reject a specific hypothesis, not whether one model is better than another. The difference between p = 0.31 and p = 0.44 with 15 data points is noise, not signal.
And here's the consequence: Cpk computed under the Weibull model might be 1.15, under lognormal 1.38, under gamma 1.27. Three "valid" fits. Three different capability conclusions. One of them goes into your PPAP package.
The Multiple Testing Problem
Distribution fitting in SPC software encourages a practice that statisticians warn against: testing multiple hypotheses on the same data and selecting the winner.
Test five distributions and select the one with the best fit statistic. The probability that at least one passes by chance — even if none is correct — increases with each distribution you test. With five candidates at α = 0.05, the family-wise error rate approaches 23%.
This isn't a theoretical concern. It's what happens every time a quality engineer opens Minitab's Individual Distribution Identification and selects "best fit" from 14+ candidates. The more options the software offers, the higher the chance of a false match.
No SPC software adjusts for multiple comparisons when fitting distributions. The "best fit" is reported without any penalty for having tried multiple alternatives. The result looks rigorous — statistical test, p-value, probability plot — but the selection process undermines the statistics.
"None of the Above" Is the Most Common Answer
The deeper problem: real manufacturing distributions often don't match any named distribution. Not because they're exotic. Because they're mixtures.
A four-cavity mold produces data that's the sum of four narrow distributions at different locations. That mixture doesn't have a name. It's not Weibull. It's not lognormal. It's not gamma. Fitting any named distribution to a mixture produces a model that's wrong everywhere — too thick in the valleys between modes, too thin at the peaks.
Non-normal data in manufacturing is frequently mixture data. Tool wear creates time-varying means. Material lots create batch-specific distributions. Shift changes create bimodal patterns. The assumption that data follows some named distribution — even a non-normal one — is itself an assumption that often fails.
When "none of the above" is the right answer, no amount of distribution fitting will produce a correct Cpk. The entire framework breaks down.
The Distribution-Free Alternative
The EGDF approach eliminates the selection step. Instead of asking "which distribution does this data follow?" it asks "what does this data look like?"
EGDF constructs a distribution function directly from measurements using information entropy. The result is a smooth function that captures whatever shape the data has — skewed, bimodal, bounded, heavy-tailed, or "none of the above." No parameter estimation. No model selection. No multiple testing penalty.
When the data genuinely follows a Weibull distribution, EGDF produces the same result as a correctly fitted Weibull. When the data is a mixture that doesn't match any named distribution, EGDF produces a correct result where distribution fitting produces a wrong one.
That's the fundamental trade: distribution fitting gives you a parametric model that may or may not be correct. Assumption-free statistics gives you a nonparametric function that's always faithful to the data.
When Distribution Fitting Still Makes Sense
Distribution fitting isn't useless. It's useful when:
You know the physics. If your process is a wear-out mechanism, Weibull is theoretically justified. The distribution choice comes from engineering knowledge, not statistical curve-fitting.
Sample size is large (n > 100). With enough data, goodness-of-fit tests have the power to distinguish between distributions, and the "best fit" is likely genuinely better.
You need a parametric model for simulation, reliability prediction, or design-of-experiments. EGDF gives you the distribution function, not a parameterized model you can plug into a Monte Carlo.
For capability analysis with typical manufacturing sample sizes (n = 10–50), distribution fitting introduces more error than it removes. The effort spent selecting a distribution would be better spent on a method that doesn't require one.
Skip the Menu. Measure the Shape.
The distribution fitting workflow was designed for an era when non-parametric methods were computationally expensive and poorly understood. In 2026, that constraint is gone.
Your data has a shape. You don't need to name it to measure it. And measuring it wrong — because you picked lognormal when the data was a mixture — costs more than not picking at all.
Upload your process data and see the actual distribution — no fitting step, no distribution menu, no wrong-model risk. Try EntropyStat free →
Your SPC software computes Cpk assuming data follows a bell curve — but 60–80% of manufacturing data doesn’t. That silent assumption produces capability numbers that are confidently wrong, costing real money in both directions.